|
A little bit ago I wrote about the Reconnaissance Blind Chess tournament and how my bot worked.
What you might notice is that for this game of RBC I used a chess engine, and had to have code around it to make up for the fact that RBC isn't really straight chess. Because of that there are some notable flaws:
If you were to try to write a tree search which took into account the sets of potential boards you would run into another problem. The imperfect information version of chess has an exponentially larger tree than regular chess, which is already a pretty massive game. In order to even approach searching that tree you would need some way of accelerating your tree search. To do this I developed a small algorithm which in my very preliminary testing gives around a 3 times speedup with logarithmic time and poly-logarithmic space complexity
0 Comments
Last summer I saw a posting about a competition called Reconnaissance Blind Chess. I have always been really fascinated by games so I decided to throw my hat in the ring.
A few weeks ago, with the competition all done, I was invited to NeurIPS by the JHUAPL to talk about how my bot worked. I figured that it might be a bit interesting to other people then, to hear how my bot worked. Writeups on how to make a basic programming language are coming soon, but for now here's v0.0.5 of Equi: https://github.com/wrbernardoni/Equi
A coding competition, and the start of classes have delayed work on Equi, so right now multithreading is only in the development branch as it is only 50% feature complete. There's a persistent bug when it comes to returning values from completed tasks, but I have the solution figured out, just not the time yet to implement it. In the meantime Equi is a fun little toy language. As soon as my schedule opens up a bit more I plan on finishing up the core parrallelism of Equi and then moving on to implementing a type system and polymorphism into Equi. For now there's just primitive types but many more features are coming to Equi. My website has been pretty static lately, as it has a habit of being. That being said, I've been far from static! Right now most of my time has been devoted to classes and many many math problem sets and readings, but I do have some software in the works. The main one should be making a debut here in a month or two and it is (drumroll please): Equi/Equicontinuous/EquiParallel -- the name is far from figured out. What it is right now is a scripting language that is slowly evolving, what it will be one day is a interpreted fully parallel programming language made for prototyping asynchronous big data programs on affordable clusters. There's a lot of work to get to those buzzwords though, and that is what I have been silently chugging away at. And it turns out that, to no one's surprise, programming languages are hard. They actually use a ton of techniques from natural language processing, because they are in their own way a language. Taking a line of code such as: if (a == b) print(a); And just understanding how it breaks down as a grammar is actually really nontrivial. You can't just read it left to right and figure out what to do (maybe this one example you can, but when it gets more complicated you cannot), because the grammar of a programming language isn't actually regular, they are usually context free. What that means is that we need to first define a grammar for our language, and then we need to find a way to work backwards from that grammar and build a "syntax tree" of what we want our code to do in a way that is more understandable for the code and in line with our intentions.
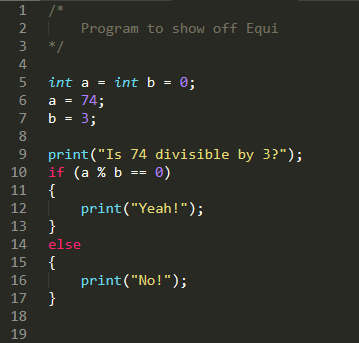
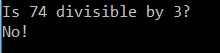
The current version just has logical operators and declarations working (as you can sorta make out from the CFG), but it does do some things.
More details will come in a little bit. I have most of the ground work done on the very basic version of Equi in this very productive weekend, so progress should speed up. Right now Equi is not turing complete, and has some very odd little quirks in the design that need to be ironed out, but as soon as it is slightly more impressive you will be sure to see it open sourced and several more write ups coming on out on a bit more of the process and ideas at work behind the code.
Recently for a class in Machine Translation I did another sort of manifold learning type task.
The premise of the problem was this: Using Google's Word2Vec you can take a sentence and learn "word embeddings", or N-dimensional euclidean vectors, that are supposed to encode the meaning of each word. Similar words should be embedded in similar places. What if you do this for two translations of a text? Can you use the word embeddings in one language to predict the embeddings in another? The answer is a solid sorta. |
AuthorHi, I'm Billy, a PhD student studying Math. Archives
January 2020
Categories
All
|


 RSS Feed
RSS Feed